Publications

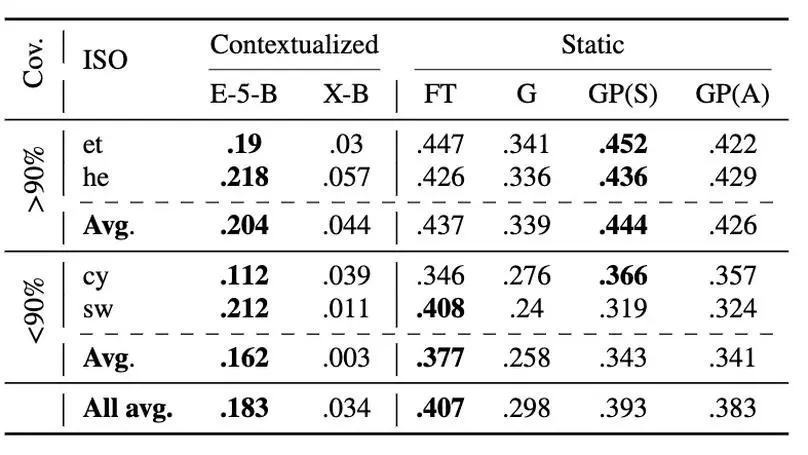
Contextualized embeddings based on large language models (LLMs) are available for various languages, but their coverage is often limited for lower resourced languages. Using LLMs for such languages is often difficult due to a high computational cost; not only during training, but also during inference. Static word embeddings are much more resource-efficient (“green”), and thus still provide value, particularly for very low-resource languages. There is, however, a notable lack of comprehensive repositories with such embeddings for diverse languages. To address this gap, we present GrEmLIn, a centralized repository of green, static baseline embeddings for 87 mid- and low-resource languages. We compute GrEmLIn embeddings with a novel method that enhances GloVe embeddings by integrating multilingual graph knowledge, which makes our static embeddings competitive with LLM representations, while being parameter-free at inference time. Our experiments demonstrate that GrEmLIn embeddings outperform state-of-the-art contextualized embeddings from E5 on the task of lexical similarity. They remain competitive in extrinsic evaluation tasks like sentiment analysis and natural language inference, with average performance gaps of just 5-10% or less compared to state-of-the-art models, given a sufficient vocabulary overlap with the target task, and underperform only on topic classification. Our code and embeddings are publicly available at https://huggingface.co/DFKI.