Abstract
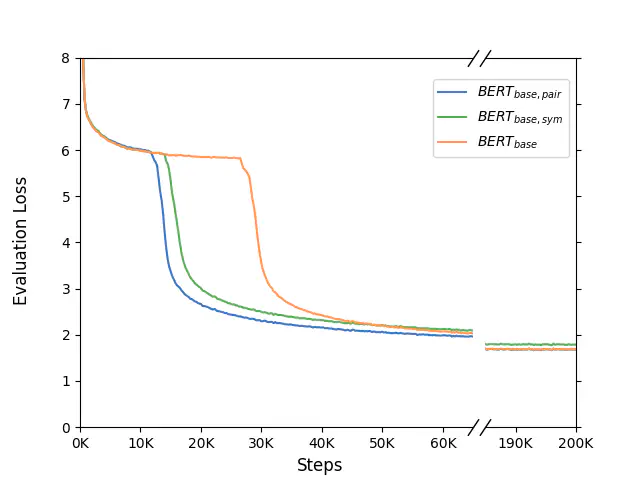
Initially introduced as a machine translation model, the Transformer architecture has now become the foundation for modern deep learning architecture, with applications in a wide range of fields, from computer vision to natural language processing. Nowadays, to tackle increasingly more complex tasks, Transformer-based models are stretched to enormous sizes, requiring increasingly larger training datasets, and unsustainable amount of compute resources. The ubiquitous nature of the Transformer and its core component, the attention mechanism, are thus prime targets for efficiency research.In this work, we propose an alternative compatibility function for the self-attention mechanism introduced by the Transformer architecture. This compatibility function exploits an overlap in the learned representation of the traditional scaled dot-product attention, leading to a symmetric with pairwise coefficient dot-product attention. When applied to the pre-training of BERT-like models, this new symmetric attention mechanism reaches a score of 79.36 on the GLUE benchmark against 78.74 for the traditional implementation, leads to a reduction of 6% in the number of trainable parameters, and reduces the number of training steps required before convergence by half.